大数据理论与实践 分布式协调服务ZooKeeper及其在软件开发中的应用
在大数据技术体系中,分布式协调服务扮演着至关重要的角色,而ZooKeeper正是这一领域的佼佼者。作为Apache旗下的开源项目,ZooKeeper为分布式应用提供了高效、可靠的协调机制,成为构建大规模分布式系统不可或缺的基础组件。
一、ZooKeeper的核心概念与架构
ZooKeeper的设计灵感来源于Google的Chubby锁服务,它采用树形结构的数据模型(称为ZNode树),每个节点可以存储少量数据。其核心特性包括:
- 顺序一致性:所有更新请求按全局顺序执行
- 原子性:更新操作要么完全成功,要么完全失败
- 单一系统映像:所有客户端看到相同的数据视图
- 可靠性:一旦更新生效,将持久化直到被覆盖
- 及时性:客户端能在可接受时间内看到最新数据
ZooKeeper集群通常由奇数个节点组成,采用领导者-追随者架构。客户端可以连接到任意节点,读写请求会被转发到领导者节点处理,确保了数据的一致性。
二、ZooKeeper在软件开发中的关键应用场景
- 配置管理:集中存储分布式系统的配置信息,当配置变更时,各节点能实时感知并更新
- 命名服务:提供类似DNS的目录服务,帮助系统定位资源
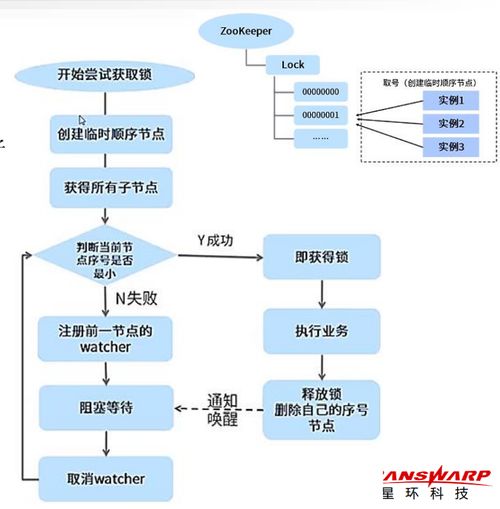
- 分布式锁:通过临时顺序节点实现互斥锁,解决分布式环境下的资源竞争问题
- 集群管理:监控节点存活状态,实现主节点选举和故障转移
- 发布订阅:通过Watch机制,客户端可以订阅特定节点的变化通知
三、实践中的最佳实践与注意事项
- 会话管理:合理设置会话超时时间,避免因网络波动导致频繁重连
- 节点设计:根据数据特性选择持久节点、临时节点或顺序节点
- Watch使用:避免设置过多Watch,防止产生“监听风暴”
- 权限控制:通过ACL机制保障数据安全
- 性能优化:将频繁访问的数据缓存到客户端,减少对ZooKeeper的直接调用
四、与大数据生态的集成
ZooKeeper已成为大数据生态系统的基础设施,众多知名项目都依赖其协调服务:
- Apache Kafka:使用ZooKeeper管理集群元数据和控制器选举
- Apache Hadoop:YARN资源管理器依赖ZooKeeper实现高可用
- Apache HBase:通过ZooKeeper管理RegionServer状态和主节点选举
- Apache Storm:使用ZooKeeper存储拓扑信息和 worker状态
五、开发实践示例
以下是一个使用Java客户端实现分布式锁的简化示例:`java
public class DistributedLock {
private ZooKeeper zk;
private String lockPath;
public boolean tryLock() throws Exception {
// 创建临时顺序节点
String node = zk.create(lockPath + "/lock",
null,
ZooDefs.Ids.OPENACLUNSAFE,
CreateMode.EPHEMERALSEQUENTIAL);
// 检查是否为最小序号节点
return checkMinNode(node);
}
public void unlock() throws Exception {
zk.delete(currentNode, -1);
}
}`
六、挑战与发展趋势
随着云原生技术的兴起,ZooKeeper也面临新的挑战和机遇:
- 容器化部署:需要适应Kubernetes等容器编排平台
- 性能优化:应对超大规模集群的协调需求
- 替代方案:etcd等新兴协调服务的竞争
- 云服务集成:各大云平台提供的托管ZooKeeper服务
ZooKeeper作为成熟的分布式协调服务,在大数据开发和分布式系统构建中具有不可替代的地位。开发者需要深入理解其原理和特性,结合具体业务场景合理使用,同时关注技术发展动态,确保系统架构的先进性和稳定性。掌握ZooKeeper不仅是大数据开发的必备技能,也是深入理解分布式系统设计思想的重要途径。
如若转载,请注明出处:http://www.zmweishi.com/product/26.html
更新时间:2026-06-19 03:47:28