Thrift简介及其在IDEA上的使用 构建高效数据处理服务
一、Thrift简介:跨语言服务开发框架
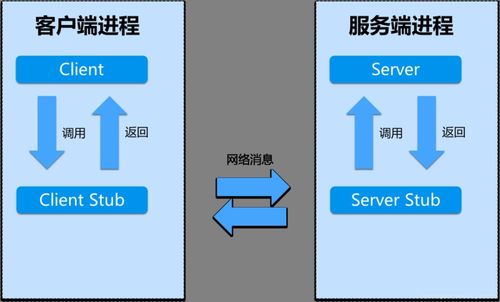
Apache Thrift 是由 Facebook(现 Meta)开发并贡献给 Apache 软件基金会的一款高效的、支持多种编程语言的远程服务调用(RPC)框架。其核心设计目标是解决跨语言服务开发与通信的复杂性,使不同技术栈的系统能够无缝协作。
主要特点与优势:
1. 跨语言支持:通过接口定义语言(IDL)定义服务接口与数据类型,然后编译生成多种目标语言(如 Java, C++, Python, Go, PHP 等)的客户端和服务端代码,实现了语言无关的通信。
2. 高性能:Thrift 提供了多种传输协议(如 TBinaryProtocol)和传输层(如 TSocket),并支持高效的序列化机制,确保了低延迟和高吞吐量的通信。
3. 清晰的架构分层:其架构明确分为服务层、传输层和协议层,开发者可以根据需要灵活选择和组合,例如使用压缩传输以节省带宽。
4. 适用于微服务:特别适合构建大规模的分布式系统、微服务架构,尤其是当服务由不同语言编写时,Thrift 是理想的通信桥梁。
在数据处理服务场景中,Thrift 常用于定义和实现数据访问接口、计算任务调度接口等,使得上游应用(如Web服务)与底层的数据处理引擎(如Spark、Flink作业或独立的计算服务)能够高效、类型安全地进行交互。
二、在 IntelliJ IDEA 中开发 Thrift 服务
IntelliJ IDEA 作为强大的 Java(及多语言)集成开发环境,为 Thrift 开发提供了良好的支持。
1. 环境准备与插件安装
* 安装 Thrift 编译器:从 Apache Thrift 官网下载对应操作系统的二进制发行版,并配置系统环境变量,确保终端可以执行 thrift --version 命令。
- 安装 IDEA 插件:在 IDEA 的插件市场中搜索并安装 "Thrift Support" 插件。该插件提供 Thrift IDL 文件的语法高亮、代码补全和结构视图,极大提升开发效率。
2. 创建项目与定义 IDL
* 新建一个 Maven 或 Gradle 项目(以Java为例)。
- 在
src/main目录下创建thrift资源文件夹,用于存放.thrift接口定义文件。
* 编写 IDL 文件,例如 DataService.thrift:
`thrift
namespace java com.example.dataservice.generated
// 定义数据结构
struct QueryRequest {
1: required string queryId,
2: optional map
3: i32 timeout = 5000
}
struct DataResult {
1: required bool success,
2: optional string data,
3: optional string errorMessage
}
// 定义服务接口
service DataProcessingService {
DataResult submitQuery(1: QueryRequest request),
string getStatus(1: string queryId),
oneway void cancelQuery(1: string queryId) // oneway表示异步调用,无需等待响应
}
`
3. 生成代码与项目配置
* 配置构建工具:在 Maven 的 pom.xml 中配置 thrift-maven-plugin,或在 Gradle 中配置相应的 Thrift 插件。这允许在编译阶段自动调用 Thrift 编译器生成指定语言的代码。
- 手动生成代码(可选):在 IDEA 的终端中,进入
thrift文件目录,执行命令,例如thrift -r --gen java DataService.thrift,生成的 Java 代码会输出到gen-java目录。通常建议将生成代码的目录(如target/generated-sources/thrift)标记为源代码根目录。
4. 实现服务端与客户端
* 服务端实现:创建类实现 Thrift 生成的 DataProcessingService.Iface 接口,并在其中填充具体的业务逻辑(如连接数据库、执行计算任务)。然后编写一个主类来创建并启动 Thrift 服务器(使用 TSimpleServer、TThreadPoolServer 等)。
- 客户端实现:在客户端项目中,同样引入生成的代码。编写客户端代码,使用
TTransport、TProtocol连接到服务端地址,并通过生成的Client类调用远程方法。
- 运行与调试:在 IDEA 中可以直接运行或调试服务端和客户端的 Main 类,就像运行普通的 Java 应用一样方便。
三、构建数据处理服务的实践要点
将 Thrift 应用于实际的数据处理服务时,有几个关键考量:
- 接口设计:IDL 设计是重中之重。数据结构和接口应清晰、稳定,并考虑向后兼容性(如使用 optional 字段、避免修改已有字段的ID)。对于数据处理服务,接口可能涉及大数据集的传输(分页/流式)、长时任务的异步状态查询和结果获取。
- 性能与稳定性:
- 传输选择:对于大数据量,考虑使用
TFramedTransport并启用压缩协议(如TCompactProtocol)。
- 服务端模型:根据并发量选择服务端模型。
TThreadPoolServer适用于常规并发,TNonblockingServer/THsHaServer适用于高并发异步场景。
- 超时与重试:在客户端务必设置合理的连接和读取超时,并实现重试机制以应对网络波动。
- 服务治理集成:在生产环境中,Thrift 服务通常需要集成到服务治理生态中,如通过 ZooKeeper、Consul 或 Nacos 进行服务注册与发现,使客户端能动态感知服务端实例。
- 监控与日志:在服务端和客户端的代码实现中,加入详细的业务日志和性能埋点,便于监控服务的健康状态、追踪请求链路和分析性能瓶颈。
****:Thrift 以其强大的跨语言能力和高性能,成为构建异构数据处理服务层的利器。结合 IntelliJ IDEA 的便捷开发环境,从接口定义、代码生成到服务实现与调试的流程非常顺畅。在设计时关注接口的清晰稳定与生产环境的健壮性要求,便能高效构建出可靠、高效的数据处理微服务。
如若转载,请注明出处:http://www.zmweishi.com/product/38.html
更新时间:2026-06-19 19:24:11